Archive for November, 2006
Open data
Posted by peanutbutter in bioinformatics, Journals Publishing, open data on November 23, 2006
Open data is a concept I came across while attending the 2nd International Digital Curation Conference and felt it deserved a post in its own right, rather than subsumed by the conference report. I am an advocate of Open Access and feel that Open Data must be a part of this process. What is the point of being able to freely read the publication if you cant freely access the data the publication refers to?
The concept of Open Data was presented to me by Peter Murray-Rust, via the DCC conference, who regularly blogs about the subject. There is a Wikipedia entry which defines the concept and a mailing list which promotes discussion of Open Data.
Steps are underway in the bio-science domain to define Minimum reporting requirements of data for repositories and publications. Two prominent examples are the MGED community with MIAME and the Proteomics community with MAIPE. Within these noble efforts there is no mention of Open Data although it seems the next logical step in the data curation pipeline;
- record the defined minimum information and metadata.
- structure and present the data.
- allow access of the data
Maybe when the effort is made to properly record, structure and describe the data, as these minimum reporting requirements advocate, the scientist and journals will be only too happy to take the next step and declare it Open Data, for the sake of scientific knowledge and progression.
2nd International Digital Curation Conference
Posted by peanutbutter in bioinformatics, conference report, Journals Publishing, open data on November 23, 2006
The Data Curation Center has just held their 2nd International Digital Curation Conference, in Glasgow. The official DCC blog for the conference tracks the thoughts and discourse over the two days and the full program can be found here. As the conference name suggests, the meeting has the particular focus on different aspects of the digital curation life-cycle including managing repositories, educating data scientists and understanding the role of policy and strategy.
One particular talk I was interested in was “The Roles of Shared Data Collections in Neuroscience”. This was presented by a social scientist, as the results of communications with Neuroscientists. Ironically the shared data collection was called “NeuroAnatomical Cell Repository” a pseudonym to “protect the confidentiality of the participants”, so much for the “shared” component! The general conclusions re-iterated what is already know in the bio-sciences; that more experiments are producing large volumes of heterogeneous data that need to be stored, preserved and presented in a manner that allows the efficient use and re-use of the data. There was particular mention that Neuroscience doesn’t have any data reporting standards, a particular buzz-topic in biological sciences.
As a result of this talk, the issue of how we publish this data was again raised, with the provoking statement from the floor, “we should bypass the traditional journals and publish the data ourselves” (a summation of the statement, not an actual quote). This is an issue I have been hearing more and more at recent conferences and in general discussions, a topic that appears to be gathering momentum. Some discourse has already been presented within this blog on some of these issues.
The open panel session on day two, engaged some interesting discussion and I heard a term which I had never heard before, “Open Data“, put forward by Peter Murray-Rust (University of Cambridge). We have all heard of Open Access publishing, (and should not be publishing any other way), but to date this means open access to the journal publication and not the the data that the publication refers to. In something as simple as a graph in a journal publication, generally the access to the numbers/values, has to be re-calculated via a print-out and a ruler. It would be so much easier (and logical) for re-use, analysis or even review, if the presented image was accompanied by the data (even if this was in an excel spreadsheet).
So in summation, the conference presented numerous issues for consideration by a “data scientist” (this may well be the new name for bioinformaticians). The concept of digital data curation is something that is becoming more prevalent in the life-sciences both at the level of the bench scientist (generating metadata) and the analysis, presentation and preservation of the resulting data. No doubt conferences like the DCC will continue to grow in stature and the issues will be further presented in their newly launched International Journal of Digital Curation.
CARMEN
Posted by peanutbutter in bioinformatics, CARMEN, Google, neuroinformatics on November 20, 2006
Today is my first day in my new job as a RA for the CARMEN project, which stands for Code, analysis, repository and modelling for e-Neuroscience. My role in this exciting project, is as a Metadata researcher for experiment context, which should involve ontology development and data representation in neuroscience.
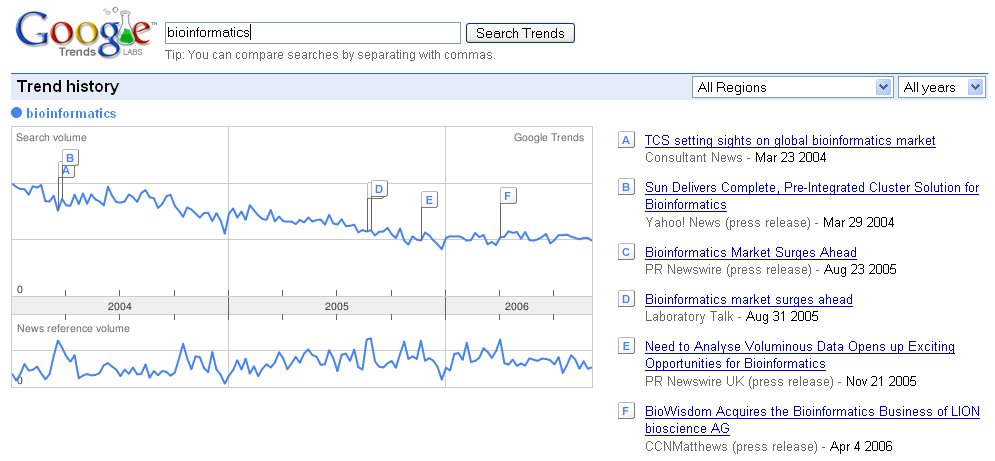
Just as a matter of interest I thought I would compare bioinformatics and neuroinformatics on Google Trends. Looks as if I have plenty of work to do!
Pubmed search engine
Posted by peanutbutter in bioinformatics, Journals Publishing on November 15, 2006
I cant lay claim that I discovered this all on my own, but as mentioned on Dan Swan’s blog PubMed can be added as a search engine in Firefox 2.0. I checked this out for Hubmed too, a much nicer interface to PubMed, with an RSS feed for search query’s and it works very well.
Digg the journals
Posted by peanutbutter in Journals Publishing, Social Media on November 4, 2006
I have been using the “user powered content” site Digg (any excuse at the moment to distract me from thesis writing) and I am enjoying the fact that the stories are coming to me with little effort, in other words I don’t have to find the blog or site first and then subscribe. One of the “stories” that I found on Digg was an interview with Matthew Sparkes, Web Executive at New Scientist, about the effects of social media on online publications (i.e Digg). It highlights the increase in social media sites such as blogging and user driven content, on the traditional media and even the traditional content providers. It stops short of saying how New Scientist are going to deal with this phenomenon but they obviously recognise the importance and impact.
Digg do have a section on science, but deals mostly with buzz stories, or media driven science reports. If this type of social media site existed specifically for the scientific domain then maybe it could go some way as to re-invent/add to, the traditional journal peer-review system, or make “community contributions” like Nature comments actually more prominent in the community? Maybe it could act as community citation system not dependant on traditional journal submissions? Or maybe a scientific community driven portal, similar to arXiv, will dispense with traditional journals altogether?
Lots of maybe’s and no answers…. An article in Wired Magazine also covers this very topic commenting on traditional peer-review and the notion of community driven content and review.
License
 This work by Frank Gibson is licensed under a Creative Commons Attribution 3.0 Unported License.
This work by Frank Gibson is licensed under a Creative Commons Attribution 3.0 Unported License.
