Archive for category neuroinformatics
CARMEN – A Scalable Science cloud
Posted by peanutbutter in bioinformatics, CARMEN, cloud, conference, data standards, neuroinformatics, open science, video on June 25, 2008
Paul Watson presents a talk on CARMEN a the Google Seattle Conference on Scalability.
CARMEN; Re-branded
Posted by peanutbutter in bioinformatics, CARMEN, neuroinformatics on June 12, 2008
![]()
We have gone through a bit of professional branding with a shiney new logo and some publicity material. The website has also been re-designed. The original drupal site was replaced with a Plone site, a decision I was not involved with. I am not sure I am a big fan of the big mug-shot which spills over the website template, the fact you have to scroll to the bottom of the front page to find out what the project is about is less than ideal. Feel free to comment
The First MIBBI Workshop: Day 1
Posted by peanutbutter in bioinformatics, CARMEN, conference, conference report, data standards, FuGE, MIBBI, neuroinformatics, ontology, open data, open science on April 2, 2008
MIBBI is a registry of scientific experiment reporting guidelines with the idea to foster a foundry of best practice to further develop and encourage modular development and re-use of reporting guidelines. The first workshop is being held at the EBI on the 2nd – 3rd April 2008 and is a relatively closed workshop to those developers and guidelines that are registered on the site. The schedule for day one is a whistle stop tour consisting of 5 min talks (adjusting for an academics interpretation of what 5 minutes means) for all the guidelines that exist, their scope and the people behind them. Due to this I am not going to comment on individual talks. I presented two talks during the day. One on CARMEN and the development of the MINI: Electrophysiology reporting guidelines, and one, standing in for Andy Jones on FuGE.
I tried sharing these slides via google presentation, they looked quite nice. However, wordpress does not seem to allow them to embed. So I put them on slide share instead. These set the tone for the discussions for the afternoon and tomorrow.
Minimum Information about a Neuroscience Investigation (MINI)
Posted by peanutbutter in bioinformatics, CARMEN, cloud, data standards, neuroinformatics, open data, open science on March 26, 2008
 The idea behind the CARMEN project is that we provide a system to store electrophysiology data and analysis services so that data can be shared and analysed in the “Neuro-cloud”. An important factor in realising this system is that the stored data and the services have to be described in a way that is both human and computationally amenable. The first stage of this is agreeing what information should actually be ascribed to the data. In other words, the balance between what the experimentalist want to say about their data and what informaticians need to know about a particular data set in order to perform their analysis. To this end we have defined what we believe to be the minimum information that must be ascribed to an electrophysiology experiment for submission to the CARMEN system. It follows the now well practised format of MIAME and MIAPE minimum reporting requirements. In the first instance the document only represents consensus within the CARMEN consortium. However, it could form the basis of a community reporting standard for electrophysiology experiments. The document is available on Nature preceedings at the following URL and comments and opinions are encouraged. http://precedings.nature.com/documents/1720/version/1
The idea behind the CARMEN project is that we provide a system to store electrophysiology data and analysis services so that data can be shared and analysed in the “Neuro-cloud”. An important factor in realising this system is that the stored data and the services have to be described in a way that is both human and computationally amenable. The first stage of this is agreeing what information should actually be ascribed to the data. In other words, the balance between what the experimentalist want to say about their data and what informaticians need to know about a particular data set in order to perform their analysis. To this end we have defined what we believe to be the minimum information that must be ascribed to an electrophysiology experiment for submission to the CARMEN system. It follows the now well practised format of MIAME and MIAPE minimum reporting requirements. In the first instance the document only represents consensus within the CARMEN consortium. However, it could form the basis of a community reporting standard for electrophysiology experiments. The document is available on Nature preceedings at the following URL and comments and opinions are encouraged. http://precedings.nature.com/documents/1720/version/1
sshh!, dont tell anyone about Data Sharing for Computational Neuroscience
Posted by peanutbutter in bioinformatics, CARMEN, data standards, neuroinformatics, ontology, open data, open science on February 18, 2008
I described in an earlier post that data sharing in Neuroscience is relatively non-existent. Some commentary on the subject has appeared since then via the 2007 SfN Satellite Symposium on Data Sharing entitled Value Added by Data SharingLong-TermPotentiation of Neuroscience Research, published in Neuroinformatics. I was also excited to see an article published last week Data Sharing for Computational Neuroscienc, also in Neuroinformatics. However, there is a caveat or two. Apart from ignoring all the data representation issues presented in other domains such as bioinformatics, the re-use of data models such as FuGE, or contribution to ontology efforts such as OBI, all these articles are not open access! How ironic, or should that be how embarrassing. Phil also covers this issue in his blog.
Oh well, looks as if there is still a challenge in the domain of Neuroscience for access to valuable insights into information flow in the brain. Who want to know how the brain works anyway? You can always pay $32 to springer if you want to find out.
Ontology crowdsourcing
Posted by peanutbutter in CARMEN, development, howto, neuroinformatics, ontology on October 31, 2007
I have the unenviable task of developing an ontology for the CARMEN project which will allow the process of electrophysiology experiments, the generated data, the analysis of the data and the services that perform the analysis, to be described, and in addition be computationally amenable. Collecting the words that are required to described these tasks are relatively trivial. However, getting the scientists to realise they have assigned numerous meanings to the same word or term requires a little bit more patience on my part.
It also requires me to educate the scientists, in that building an ontology for electrophysiology is a little more complicated than putting some “words” in a text file.
The words in an ontology have to be explicitly defined so as to be completely unambiguous both to the scientist, who generate the data, and the informaticians who want to analyse the data, either immediately or several years down the line. The data should be described in such a manner to an agreed level of detail that no longer requires the informatician to pick up the phone and politely ask “how did you generate this piece of data?”.
The first stage I am trying to overcome or relay to the scientists is that although you use the same “words” you often use the words to describe different things in different contexts. This situation is generally less important when described in a journal publication but in presents issues when you use the words to annotate data and infer knowledge.
I have been trying to work out the best way to get this message across and to develop a methodology for collecting agreed definitions for words. I could have always put up a wiki or an issue tracker to do this, but this doesn’t always guarantee contribution. I feel the process needs to be mediated to turn the natural language definitions into more explicit normalised ontological definitions. Taking this into account I have decided to apply crowdsourcing to Ontology development.
Simply this means sending an email out entitled “Metadata term of the week”. This process was suggested to me by my boss Phil Lord. In this email I pick a word and attempt to define it. If I get it right then there is no need to respond. If you disagree with the definition then you have to respond with an alternative and therefore a discussion ensues and ends with an agreed definition. With this process the scientists get to see that other scientists within the project define or describe words slightly differently enough that they no longer are talking about the same thing.
The first Metadata term of the week was “spike sorting” and we received the following definitions
- Spike sorting is a process of assigning data spikes to sets, where each set is identified with a single neuron
- Spike sorting is a process aiming at separating spikes generated by different cells based on shape discrimination algorithms
- Spike sorting is a technique used in single-cell neural recordings which assigns particular spike shapes to individual neurons
- Spike sorting is a classification procedure. We can think about a forest (time series) where M animals of K different types live (M spikes of K different neurons). All animals are different but say two rabbits are a little bit more similar than the rabbit and fox. So, we need classify all M animals and to say about each to what particular class among K classes this animal belongs.
- Spike sorting is the process of identifying the waveforms associated with action potentials of an individual neuron within time series data.
All trying to say the same thing, although when taken explicitly they start to “mean” different things. Which led us to defining a three more terms in order to answer the original question:
a) An action potential is a sudden depolarization of the membrane potential of a cell . [synonym: spike]
b) Spike detection is a data extraction process that classifies the waveforms associated with action potentials and identifies the time point of when the spike event initiates. The input to this process is a continuous waveform. The output is a single sequence of spike event times.
c) Spike sorting is a data extraction process that assigns detected spike event times to individual neurons. The input of this process can be a continuous waveform or a sequence of spike event times. The output of this process are sets(or categories) of spikes. Each set is assumed to correspond to a single neuron.
This peer-production processes took approximately 4 days to conclude and I think it has succeeded in addressing three issues
- Highlighting the ambiguity and the use of terms, even within a small and enclosed group of scientist, within a single project.
- The peer-production of ontology terms and definitions.
- The engagement of the community within the project.
I would love to know peoples comments on this process or any alternative suggestions. Feel free to comment.
Do scientists really believe in open science?
Posted by peanutbutter in bioinformatics, CARMEN, data standards, Journals Publishing, MIBBI, neuroinformatics, ontology, open data, open science, Social Media on June 26, 2007
I am writing this post as a collection of the current status and opinions of “Open Science”. The main reason being I have a new audience; I am working for the CARMEN e-Neuroscience project. This has exposed me, first hand, to a domain of the life-sciences to which data sharing and publicly exposing methodologies has not been readily adopted, largely it is claimed due to the size of the data in question and sensitive privacy issues.
Ascoli, 2006 also endorses this view of the neuroscience and offers some further reasons why this is the case . He also includes the example of exposing neuronal morphological data and argues the benefits and counters the reticence to sharing this type of data.
Hopefully, as the motivation for the CARMEN project is to store and share and facilitate the analysis of neuronal activity data, some of these issues can be overcome.
With this in mind I want to create this post to provide a collection of specific blogs, journal articles, relevant links and opinions which hopefully will be a jumping-off point to understanding the concept of Open Science and embracing the future methodologies in pushing the boundaries of scientific knowledge.
What is Open Science?
There is no hard and fast definition, although according to the Wikipedia entry:
“Open Science is a general term representing the application of various Open approaches (Open Source, Open Access, Open Data) to scientific endeavour. It can be partially represented by the Mertonian view of Science but more recently there are nuances of the Gift economy as in Open source culture applied to science. The term is in intermittent and somewhat variable use.”
“Open Science” encompasses the ideals of transparent working practices across all of the life-science domains, to share and further scientific knowledge. It can also be thought of to include the complete and persistent access to the original data from which knowledge and conclusions have been extracted. From the initial observations recorded in a lab-book to the peer-reviewed conclusions of a journal article.
The most comprehensive overview is presented by Bill Hooker over at 3quarks daily. He has written three sections under the title “The Future of Science is open”
In part 1, as the title suggests, Bill presents an overview on open access publishing and how this can lead to open-science (part 2). He suggests that
“For what I am calling Open Science to work, there are (I think) at least two further requirements: open standards, and open licensing.”
I don’t want to repeat the content already contained in these reviews, although I agree with Bill’s statement here. There is no point in having an open science philosophy if the data in question is not described or structured in a form that facilitates exchange, dissemination and evaluation of the data, hence the requirement of standards.
I am unaware of community endorsed standard reporting formats within Neuroscience. However, the proliferation of standards in Biology and Bioinformatics, is such, that it is fast becoming a niche domain in its own right. So much so, that there now exists a registry for Minimum Information reporting guidelines, following in the formats of MIAME and MIAPE. This registry is called MIBBI (Minimum Information for Biological and Biomedical Investigations) and aims to act as a “one-stop-shop” of existing standards life-science standards. MIBBI also provides a foundry where best practice for standards design can be fostered and disparate domains can integrate and agree on common representations of reporting guidelines for common technologies.
Complementary to standard data structures and minimum reporting requirements, is the terminology used to described the data; the metadata. Efforts are under way to standardise terminology which describes experiments, essential in an open environment, or simply in a collaboration. This is the goal of the Ontology of Biomedical Investigations (OBI) project which is developing “an integrated ontology for the description of biological and medical experiments and investigations. This includes a set of ‘universal’ terms, that are applicable across various biological and technological domains, and domain-specific terms relevant only to a given domain“. Already OBI is gaining momentum and currently supports diverse communities from Crop science to Neuroscience.
Open licensing of data may address the common arguments I hear for not releasing data, that “somebody might use it”, or the point blank refusal of “not until I publish my paper”. This is an unfortunate side effect of the “publish or perish” system as commented on bbgm and Seringhaus and Gerstein, 2007, and really comes down to due credit. In most cases this prevents real time assessment of research, complementary analysis or cross comparisons with other data sets to occur alongside the generation of the data, which would in no doubt enforce the validity of the research. Assigning computational amenable licenses to data, such as those proposed by Science Commons, maybe one way of ensuring that re-use of the data is always credited to the laboratory that generated the data. It is possible paradigm that “Data accreditation impact factors” could exist analogous to the impact factors of traditional peer-reviewed journals.
Open science may not just be be about releasing data associated with a peer-review journal, rather it starts from exposing the daily recordings and observations of an investigation, contained in the lab-book. One aspect of the “Open data” movement is that of “Open Notebook Science” a movement pioneered by Jean-Claude Bradley and the Useful Chemistry group, where their lab-book is is open and access-able on-line. This open notebook method was further discussed by a recent Nature editorial outlining the benefits of this approach. Exposing you lab-book could allow you to link the material and methods section of your publication, proving you actually did the work and facilitating the prospect of other researchers actually being able to repeat your ground breaking experiments.
Already many funders are considering data management or data sharing policies, to be applied to future research proposals. The BBSRC have recently released their data sharing policy which states that, “all research proposals submitted to BBSRC from 26th April 2007 must now include a statement on data sharing. This should include concise plans for data management and sharing or provide explicit reasons why data sharing is not possible or appropriate“. With these types of policies a requirement to research funding the “future of science is open“.
The “Open Science” philosophy appears to be gaining some momentum as is actively being discussed within the scientific blogosphere. This should not really come as a great surprise as science blogging can be seen as part of the “Open science” movement, openly sharing opinions and discourse. Some of the more prominent science blogs focusing on the open science ideal are Open access News, Michael Eisen’s Open Science Blog, Research Remix, Science Commons, Peter Murray-Rust.
There are of course alot more blogs discussing the issue. Performing an “open science search” on Postgenomic (rss feed on search terms please, Postgenomic) produces an up to the minute list of the open science discourse. Although early days, maybe even the “open science” group on Scintilla (still undecided on Scintilla) will be the place in the future for fostering the open science community.
According to Bowker’s description of the traditional model of scientific publishing, the journal article “forms the archive of scientific knowledge” and therefore there has been no need to hold on to the data after it has been “transformed” into a paper. This, incorporated with in-grained social fears, as a result of “publish or perish”, of not letting somebody see the experimental data before they get their peer-reviewed publication, will cripple the open science movement and slow down knowledge discovery. Computational amenable licences may go some way to solve this. But raising the awareness and a clear memorandum from the major journal publishers that, exposing real-time science and publishing data will not prevent publication as a peer-reviewed journal, can only help.
In synopsis I will quote Bill again as I think he presents a summary better than I could;
“My working hypothesis is that open, collaborative models should out-produce the current standard model of research, which involves a great deal of inefficiency in the form of secrecy and mistrust. Open science barely exists at the moment — infancy would be an overly optimistic term for its developmental state. Right now, one of the most important things open science advocates can do is find and support each other (and remember, openness is inclusive of a range of practices — there’s no purity test; we share a hypothesis not an ideology). “
CARMEN
Posted by peanutbutter in bioinformatics, CARMEN, Google, neuroinformatics on November 20, 2006
Today is my first day in my new job as a RA for the CARMEN project, which stands for Code, analysis, repository and modelling for e-Neuroscience. My role in this exciting project, is as a Metadata researcher for experiment context, which should involve ontology development and data representation in neuroscience.
Just as a matter of interest I thought I would compare bioinformatics and neuroinformatics on Google Trends. Looks as if I have plenty of work to do!
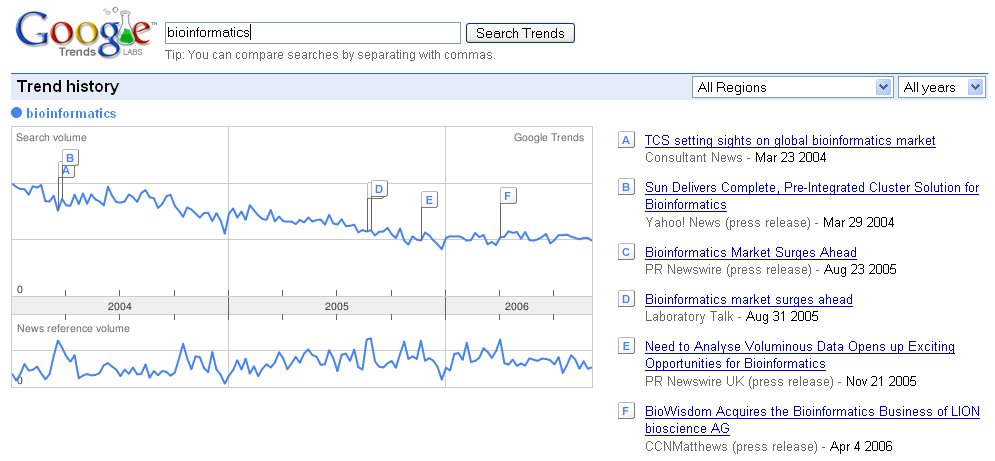
License
 This work by Frank Gibson is licensed under a Creative Commons Attribution 3.0 Unported License.
This work by Frank Gibson is licensed under a Creative Commons Attribution 3.0 Unported License.
