Do scientists really believe in open science?
Posted by peanutbutter in bioinformatics, CARMEN, data standards, Journals Publishing, MIBBI, neuroinformatics, ontology, open data, open science, Social Media on June 26, 2007
I am writing this post as a collection of the current status and opinions of “Open Science”. The main reason being I have a new audience; I am working for the CARMEN e-Neuroscience project. This has exposed me, first hand, to a domain of the life-sciences to which data sharing and publicly exposing methodologies has not been readily adopted, largely it is claimed due to the size of the data in question and sensitive privacy issues.
Ascoli, 2006 also endorses this view of the neuroscience and offers some further reasons why this is the case . He also includes the example of exposing neuronal morphological data and argues the benefits and counters the reticence to sharing this type of data.
Hopefully, as the motivation for the CARMEN project is to store and share and facilitate the analysis of neuronal activity data, some of these issues can be overcome.
With this in mind I want to create this post to provide a collection of specific blogs, journal articles, relevant links and opinions which hopefully will be a jumping-off point to understanding the concept of Open Science and embracing the future methodologies in pushing the boundaries of scientific knowledge.
What is Open Science?
There is no hard and fast definition, although according to the Wikipedia entry:
“Open Science is a general term representing the application of various Open approaches (Open Source, Open Access, Open Data) to scientific endeavour. It can be partially represented by the Mertonian view of Science but more recently there are nuances of the Gift economy as in Open source culture applied to science. The term is in intermittent and somewhat variable use.”
“Open Science” encompasses the ideals of transparent working practices across all of the life-science domains, to share and further scientific knowledge. It can also be thought of to include the complete and persistent access to the original data from which knowledge and conclusions have been extracted. From the initial observations recorded in a lab-book to the peer-reviewed conclusions of a journal article.
The most comprehensive overview is presented by Bill Hooker over at 3quarks daily. He has written three sections under the title “The Future of Science is open”
In part 1, as the title suggests, Bill presents an overview on open access publishing and how this can lead to open-science (part 2). He suggests that
“For what I am calling Open Science to work, there are (I think) at least two further requirements: open standards, and open licensing.”
I don’t want to repeat the content already contained in these reviews, although I agree with Bill’s statement here. There is no point in having an open science philosophy if the data in question is not described or structured in a form that facilitates exchange, dissemination and evaluation of the data, hence the requirement of standards.
I am unaware of community endorsed standard reporting formats within Neuroscience. However, the proliferation of standards in Biology and Bioinformatics, is such, that it is fast becoming a niche domain in its own right. So much so, that there now exists a registry for Minimum Information reporting guidelines, following in the formats of MIAME and MIAPE. This registry is called MIBBI (Minimum Information for Biological and Biomedical Investigations) and aims to act as a “one-stop-shop” of existing standards life-science standards. MIBBI also provides a foundry where best practice for standards design can be fostered and disparate domains can integrate and agree on common representations of reporting guidelines for common technologies.
Complementary to standard data structures and minimum reporting requirements, is the terminology used to described the data; the metadata. Efforts are under way to standardise terminology which describes experiments, essential in an open environment, or simply in a collaboration. This is the goal of the Ontology of Biomedical Investigations (OBI) project which is developing “an integrated ontology for the description of biological and medical experiments and investigations. This includes a set of ‘universal’ terms, that are applicable across various biological and technological domains, and domain-specific terms relevant only to a given domain“. Already OBI is gaining momentum and currently supports diverse communities from Crop science to Neuroscience.
Open licensing of data may address the common arguments I hear for not releasing data, that “somebody might use it”, or the point blank refusal of “not until I publish my paper”. This is an unfortunate side effect of the “publish or perish” system as commented on bbgm and Seringhaus and Gerstein, 2007, and really comes down to due credit. In most cases this prevents real time assessment of research, complementary analysis or cross comparisons with other data sets to occur alongside the generation of the data, which would in no doubt enforce the validity of the research. Assigning computational amenable licenses to data, such as those proposed by Science Commons, maybe one way of ensuring that re-use of the data is always credited to the laboratory that generated the data. It is possible paradigm that “Data accreditation impact factors” could exist analogous to the impact factors of traditional peer-reviewed journals.
Open science may not just be be about releasing data associated with a peer-review journal, rather it starts from exposing the daily recordings and observations of an investigation, contained in the lab-book. One aspect of the “Open data” movement is that of “Open Notebook Science” a movement pioneered by Jean-Claude Bradley and the Useful Chemistry group, where their lab-book is is open and access-able on-line. This open notebook method was further discussed by a recent Nature editorial outlining the benefits of this approach. Exposing you lab-book could allow you to link the material and methods section of your publication, proving you actually did the work and facilitating the prospect of other researchers actually being able to repeat your ground breaking experiments.
Already many funders are considering data management or data sharing policies, to be applied to future research proposals. The BBSRC have recently released their data sharing policy which states that, “all research proposals submitted to BBSRC from 26th April 2007 must now include a statement on data sharing. This should include concise plans for data management and sharing or provide explicit reasons why data sharing is not possible or appropriate“. With these types of policies a requirement to research funding the “future of science is open“.
The “Open Science” philosophy appears to be gaining some momentum as is actively being discussed within the scientific blogosphere. This should not really come as a great surprise as science blogging can be seen as part of the “Open science” movement, openly sharing opinions and discourse. Some of the more prominent science blogs focusing on the open science ideal are Open access News, Michael Eisen’s Open Science Blog, Research Remix, Science Commons, Peter Murray-Rust.
There are of course alot more blogs discussing the issue. Performing an “open science search” on Postgenomic (rss feed on search terms please, Postgenomic) produces an up to the minute list of the open science discourse. Although early days, maybe even the “open science” group on Scintilla (still undecided on Scintilla) will be the place in the future for fostering the open science community.
According to Bowker’s description of the traditional model of scientific publishing, the journal article “forms the archive of scientific knowledge” and therefore there has been no need to hold on to the data after it has been “transformed” into a paper. This, incorporated with in-grained social fears, as a result of “publish or perish”, of not letting somebody see the experimental data before they get their peer-reviewed publication, will cripple the open science movement and slow down knowledge discovery. Computational amenable licences may go some way to solve this. But raising the awareness and a clear memorandum from the major journal publishers that, exposing real-time science and publishing data will not prevent publication as a peer-reviewed journal, can only help.
In synopsis I will quote Bill again as I think he presents a summary better than I could;
“My working hypothesis is that open, collaborative models should out-produce the current standard model of research, which involves a great deal of inefficiency in the form of secrecy and mistrust. Open science barely exists at the moment — infancy would be an overly optimistic term for its developmental state. Right now, one of the most important things open science advocates can do is find and support each other (and remember, openness is inclusive of a range of practices — there’s no purity test; we share a hypothesis not an ideology). “
Semantic Web for e-science
Posted by peanutbutter in semantic web on May 30, 2007
BMC bioinformatics has released a special issue supplement on the Semantic e-science for biomedicine. It contain six papers on “the-state-of-the-art” concerning the use of semantic web technologies in the life-sciences or biomedicine. The topics covered range from modelling networks and pathways to, intriguingly “traditional Chinese Medicine”.
One of the papers Advancing translational medicine research with the semantic web presents an overview of the W3C Semantic Web Health Care and Life Sciences Interest Group (HCLSIG). This paper describes the work of HCLSIG and a use-case example covering the achievements as well as the future directions of the group. Unlike many “Semantic Web” papers I have read before it presents a well grounded view of the technologies and challenges of the semantic web in biomedince and does not proclaim to solve the bio-data problem by applying a new set of technologies to the issues.
No more session restore in Firefox
Posted by peanutbutter in Uncategorized on March 7, 2007
I continually get greeted with the “restore last session” pop-up when I start firefox. I find it really annoying especially as I use Google Browser sync to do exactly the same thing, so I have to deal with two restore messages. I have followed the following link and turned off the session restore feature in firefox.
1. type about:config in your browser URL
2. go to the browser.sessionstore.enabled setting
3. change the setting to false
One foot on the cloud
Posted by peanutbutter in General on February 22, 2007
I am starting to realise that I am handing more and more applications over to the “cloud”. A term apparently coined by Google CEO Eric Schmid to describe web based applications and data storage. My cloud is currently composed of
- my email and calendar application,
- Bloglines ; to keep up to date with my favourite blogs,
- Connotea ; for my reference library,
- a personal wiki for general note taking,
- Basecamp for project management, but I mostly use the to-do list feature.
- My bookmarks are managed by a combination of Connotea, del.icio.us and Google browser sync
- and of course this blog
I suppose the only thing left for day to day work would be the office tools. I have started looking at Google docs and I think it would be very useful for collaborative documents rather than 10 different commented versions of a documenting flying around via email.
An artical on Wired gives a lengthy summary of the “Internet Cloud”. I suppose the assumption is that a desktop PC will become a thing of the past, or rather just a tool to connect to your cloud, which I am warming to after having to re-install windows on my laptop, due to technical difficulties.
Life-science data standards
Posted by peanutbutter in bioinformatics, data standards, Journals Publishing, open data on January 12, 2007
The full complement of the Human Proteome Organisation (HUPO) Proteomics Standards Initiative (PSI), Minimum Information About a Proteomics Experiment (MIAPE), recommended reporting guidelines are now available for community review on the Nature Biotechnology website.
The manuscripts range from the definition of the MIAPE concept to the individual guidelines themselves which cover, Mass Spectrometry, Mass Spectrometry Informatics, Gel Electrophoresis and Molecular Interaction experiments. A further paper on the PSI protein modification ontology (PSI-MOD) is also listed.
Several other Minimum reporting requirements are also listed from other domains such as genome sequences (MIGS) and in Situ Hybridization and Immunochemistry (MISFISHIE).
There is also a paper on the Functional Genomics Experiment Model (FUGE) which is an “extensible framework” or data model for standards in functional genomics, although equally extensible to most scientific experiments.
As this process of community review, hosted on the Nature Biotech website, is a relatively new process and open to anyone, both identified or anonymous, I would encourage anybody with the relevant knowledge to comment on the papers. A greater response from the community ultimately means the guidelines are actually representative of the domain and technology they represent.
Semantic Web: Revolutionizing Knowledge Discovery in the Life Sciences
Posted by peanutbutter in bioinformatics, ontology on December 14, 2006
A new book has been released on the Semantic Web and the applications in Life sciences, intuitively entitled Sematic Web: Revolutionizing Knowledge Discovery in the Life Sciences. I have purchased a similar book before entitled Ontologies for Bioinformatics and was not overly impressed with its content. This book however, as pointed out by Duncan on Nodalpoint is written by people who are actually using the technology, I have met several of the people involved in authoring some of the chapters and I think I will definitely be purchasing a copy, or rather the lab will be purchasing a copy.
Open data
Posted by peanutbutter in bioinformatics, Journals Publishing, open data on November 23, 2006
Open data is a concept I came across while attending the 2nd International Digital Curation Conference and felt it deserved a post in its own right, rather than subsumed by the conference report. I am an advocate of Open Access and feel that Open Data must be a part of this process. What is the point of being able to freely read the publication if you cant freely access the data the publication refers to?
The concept of Open Data was presented to me by Peter Murray-Rust, via the DCC conference, who regularly blogs about the subject. There is a Wikipedia entry which defines the concept and a mailing list which promotes discussion of Open Data.
Steps are underway in the bio-science domain to define Minimum reporting requirements of data for repositories and publications. Two prominent examples are the MGED community with MIAME and the Proteomics community with MAIPE. Within these noble efforts there is no mention of Open Data although it seems the next logical step in the data curation pipeline;
- record the defined minimum information and metadata.
- structure and present the data.
- allow access of the data
Maybe when the effort is made to properly record, structure and describe the data, as these minimum reporting requirements advocate, the scientist and journals will be only too happy to take the next step and declare it Open Data, for the sake of scientific knowledge and progression.
2nd International Digital Curation Conference
Posted by peanutbutter in bioinformatics, conference report, Journals Publishing, open data on November 23, 2006
The Data Curation Center has just held their 2nd International Digital Curation Conference, in Glasgow. The official DCC blog for the conference tracks the thoughts and discourse over the two days and the full program can be found here. As the conference name suggests, the meeting has the particular focus on different aspects of the digital curation life-cycle including managing repositories, educating data scientists and understanding the role of policy and strategy.
One particular talk I was interested in was “The Roles of Shared Data Collections in Neuroscience”. This was presented by a social scientist, as the results of communications with Neuroscientists. Ironically the shared data collection was called “NeuroAnatomical Cell Repository” a pseudonym to “protect the confidentiality of the participants”, so much for the “shared” component! The general conclusions re-iterated what is already know in the bio-sciences; that more experiments are producing large volumes of heterogeneous data that need to be stored, preserved and presented in a manner that allows the efficient use and re-use of the data. There was particular mention that Neuroscience doesn’t have any data reporting standards, a particular buzz-topic in biological sciences.
As a result of this talk, the issue of how we publish this data was again raised, with the provoking statement from the floor, “we should bypass the traditional journals and publish the data ourselves” (a summation of the statement, not an actual quote). This is an issue I have been hearing more and more at recent conferences and in general discussions, a topic that appears to be gathering momentum. Some discourse has already been presented within this blog on some of these issues.
The open panel session on day two, engaged some interesting discussion and I heard a term which I had never heard before, “Open Data“, put forward by Peter Murray-Rust (University of Cambridge). We have all heard of Open Access publishing, (and should not be publishing any other way), but to date this means open access to the journal publication and not the the data that the publication refers to. In something as simple as a graph in a journal publication, generally the access to the numbers/values, has to be re-calculated via a print-out and a ruler. It would be so much easier (and logical) for re-use, analysis or even review, if the presented image was accompanied by the data (even if this was in an excel spreadsheet).
So in summation, the conference presented numerous issues for consideration by a “data scientist” (this may well be the new name for bioinformaticians). The concept of digital data curation is something that is becoming more prevalent in the life-sciences both at the level of the bench scientist (generating metadata) and the analysis, presentation and preservation of the resulting data. No doubt conferences like the DCC will continue to grow in stature and the issues will be further presented in their newly launched International Journal of Digital Curation.
CARMEN
Posted by peanutbutter in bioinformatics, CARMEN, Google, neuroinformatics on November 20, 2006
Today is my first day in my new job as a RA for the CARMEN project, which stands for Code, analysis, repository and modelling for e-Neuroscience. My role in this exciting project, is as a Metadata researcher for experiment context, which should involve ontology development and data representation in neuroscience.
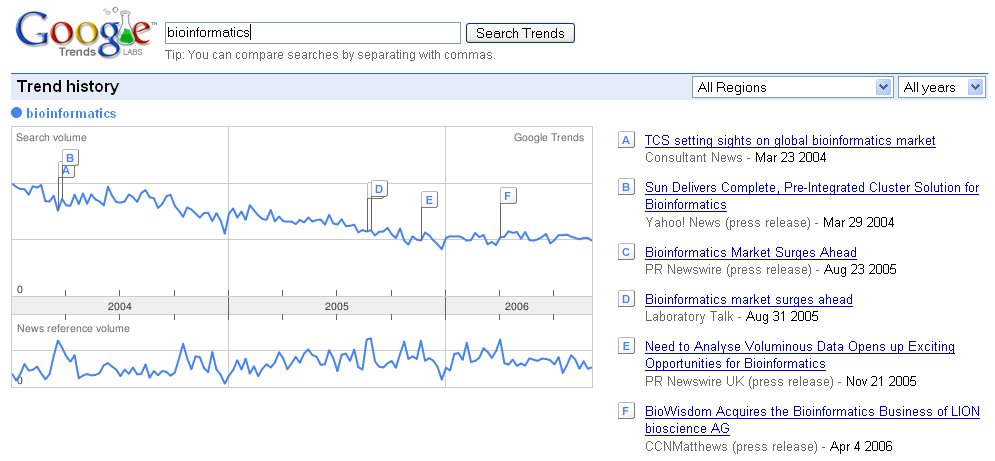
Just as a matter of interest I thought I would compare bioinformatics and neuroinformatics on Google Trends. Looks as if I have plenty of work to do!
Pubmed search engine
Posted by peanutbutter in bioinformatics, Journals Publishing on November 15, 2006
I cant lay claim that I discovered this all on my own, but as mentioned on Dan Swan’s blog PubMed can be added as a search engine in Firefox 2.0. I checked this out for Hubmed too, a much nicer interface to PubMed, with an RSS feed for search query’s and it works very well.
License
 This work by Frank Gibson is licensed under a Creative Commons Attribution 3.0 Unported License.
This work by Frank Gibson is licensed under a Creative Commons Attribution 3.0 Unported License.
